Die Programmiersprache Python zeichnet sich unter anderem durch Einfachheit, Übersichtlichkeit und eine reduzierte Syntax aus. Die SAP Data Warehouse Cloud (DWC) mit der lokalen Python-Umgebung zu verbinden, bringt mehrere Vorteile mit sich. Die lokale Umgebung kann als Testumgebung für die Data Flows in der SAP DWC genutzt werden. Da die Data Flows bislang die Frameworks Panda und Numpy beinhalten, sollte man sich auch in der Python-Umgebung auf diese Frameworks beschränken.
Die Python-Umgebung lässt sich jedoch auch dazu nutzen, die SAP Data Warehouse Cloud mit Daten anzureichern, die beispielsweise durch nicht unterstützte Frameworks erlangt oder gar von einer REST-Schnittstelle mit Python ausgelesen werden. Wir zeigen, wie Anwender die SAP Data Warehouse Cloud mit der lokalen Python-Umgebung verbinden und damit Views von der SAP DWC auslesen sowie neue Tabellen in die SAP DWC schreiben können.
Sie möchten Ihr Data Warehousing in die Cloud bringen?

Lesen Sie mehr zur SAP Data Warehouse Cloud
- Wie Sie SAP Data Warehouse Cloud mit Power BI und Tableau verbinden
- Zusammenspiel von SAP Data Warehouse Cloud und KNIME
- Auf Spurensuche: Audit Logging in der SAP Data Warehouse Cloud
- SAP Data Warehouse Cloud und Python: Eine lohnende Verbindung
Vorbereitungen in der SAP Data Warehouse Cloud
Damit die Daten in Python gelesen und anschließend wieder in die SAP DWC importiert werden, gilt es, zunächst die SAP Data Warehouse Cloud für die Anbindung vorzubereiten. Dazu sind folgende Schritte notwendig:
-
Anlegen eines Datenbankbenutzers
-
Freigeben der öffentlichen IP-Adresse für die SAP Data Warehouse Cloud
-
Freigeben der Views für den Verbrauch
Welche Vorbereitungen in der SAP Data Warehouse Cloud zu treffen sind, haben wir in einem anderen Blogbeitrag beschrieben. Zusätzlich muss Anaconda 3 auf dem Endgerät installiert werden, um Python und die Entwicklungsumgebung Spyder nutzen zu können. Ist Anaconda 3 installiert, sollte auch Spyder auf dem Endgerät verfügbar sein.
Installationen in Python
Nach dem Öfffnen von Spyder und dem Erstellen einer neuen Datei muss der Anwender verschiedene Installationen durchführen. Das betrifft unter anderem die Bibliothek SQLAlchemy. Sie ist leichter zu bedienen als die Bibliothek hdbcli, da sich Tabellen ohne SQL erstellen lassen. Mit Blick auf SQLAlchemy sind in diesem Fall zwei Installationen erforderlich: das normale Framework und die HANA-spezifische Erweiterung. Auf die Installation von hdbcli kann jedoch nicht verzichtet werden, da diese Bibliothek für die Authentifizierung benötigt wird.

Import der Bibliotheken
Der nächste Schritt besteht darin, die Importe für das Skript anzugeben. Hierfür wird das OS-Modul benötigt, um auf Funktionen des Betriebssystems zugreifen zu können. Zudem werden Panda und die zuvor installierte Bibliothek SQLAlchemy importiert. Von SQLAlchemy ist zusätzlich noch die Funktion create_engine erforderlich. Hdbcli und dbapi werden benötigt, um die Authentifizierung durchzuführen. Die letzte Codezeile ist optional, darauf gehen wir weiter unten genauer ein.

Verbindung zur SAP Data Warehouse Cloud
Nun ist das Skript bereit für die Verbindung zur SAP Data Warehouse Cloud. Zuerst gilt es, die Daten des erstellten Datenbankbenutzers anzulegen. Sie sind im Space-Management der SAP DWC im Info-Dialogfeld des entsprechenden Datenbankbenutzers zu finden.
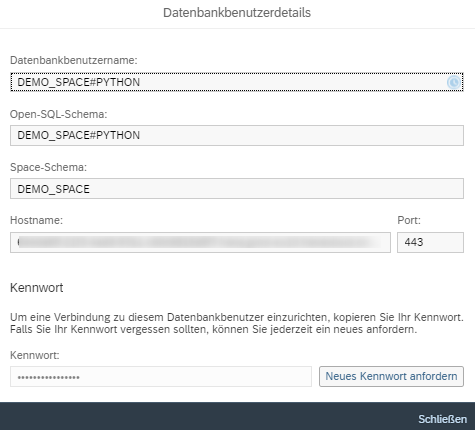
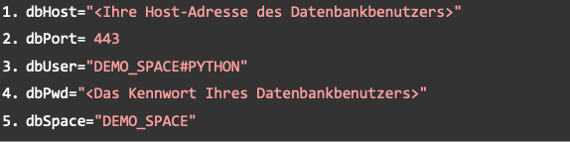
Anschließend muss die create_engine-Funktion aufgerufen werden. Sie enthält die angegebenen Daten des Datenbankbenutzers. Wichtig dabei ist, dass der Punkt „encrypt“ mit „true“ hinterlegt ist, sonst lässt die SAP Data Warehouse Cloud die Verbindung nicht zu.
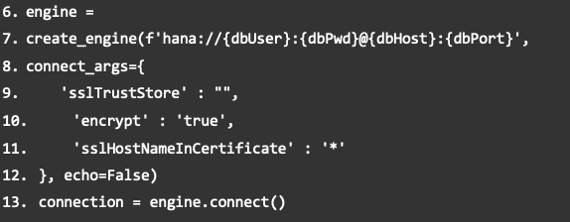
Falls die folgende Fehlermeldung erscheint, stellen Sie sicher, dass die richtige IP-Adresse freigegeben wurde. Sie können sie beispielsweise auf der Seite WieistmeineIP.de überprüfen.

Auslesen von Views
Um einen View auszulesen, muss zunächst der Name des Views in eine Variable geschrieben werden. Dabei spielt die Groß- und Kleinschreibung eine wichtige Rolle. Daraufhin lässt sich mit der Panda-Funktion read_sql_table der angegebene View auslesen und mit „print“ in der Konsole ausgeben.

Erstellen eines Views in der SAP DWC
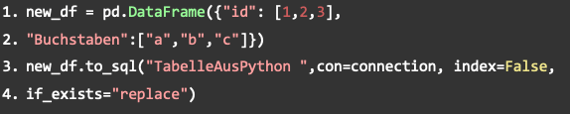
Die Erstellung des DataFrames soll als einfaches Beispiel dienen. An dieser Stelle kann eine beliebige Tabelle erstellt werden. Der wichtige Teil ist die zweite Spalte, in der die Tabelle in die SAP Data Warehouse Cloud geschrieben wird. Der Name ist frei wählbar, in unserem Beispiel lautet er „TabelleAusPython“. Die Variable con sollte hingegen mit der Variable belegt werden, in der engine.connect() gespeichert wurde. „Index“ gibt an, ob die Tabelle einen Index haben soll oder nicht. „If_exists“ ist mit „replace“ belegt, sodass die Tabelle überschrieben wird, falls bereits eine gleichnamige Tabelle vorhanden ist.
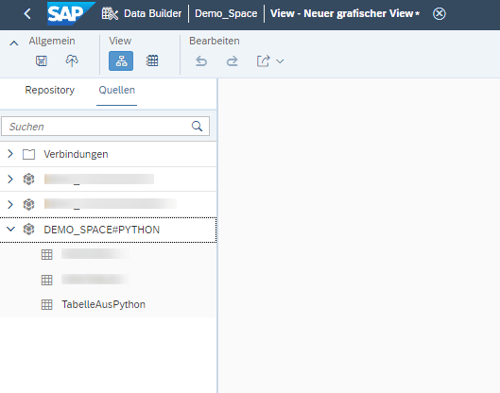
Nachdem das Skript ausgeführt wurde, ist die Tabelle in der SAP Data Warehouse Cloud zu finden. Der Anwender kann nun einen neuen View erstellen, die Tabelle unter Quellen/Datenbankbenutzer sehen und sie zum Modellieren verwenden.
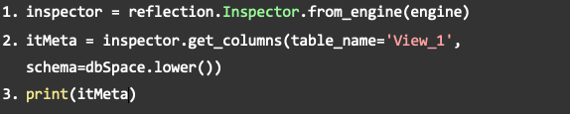
Und was ist „reflection“?
Bei den Importen wurde optional die Bibliothek reflection vorgeschlagen. Sie ist für die Anbindung nicht zwingend notwendig, bietet aber spannende Möglichkeiten. Denn mit dieser Funktion lassen sich beispielsweise die Metadaten des Views auslesen.